Text classification for Stater

- Published on
- Duration
- 5 months
- Role
- Product owner & Developer
During my semester in data science at Windesheim, I had the opportunity to work on an exciting project for Stater, a leading company that specializes in mortgage management for lenders, banks, and insurance companies. The project aimed to explore the effectiveness of AI-based text classification, specifically through the use of embeddings, in comparison to traditional analysis methods like Support Vector Machines (SVM).
As the product owner of the project, my primary responsibility was to ensure effective communication between Stater, Windesheim, and our project group. However, an administrative oversight occurred, leading to the assignment being accepted even though AI was not part of the semester curriculum. This situation presented a unique challenge, as I needed to find a solution that would satisfy both Stater's expectations and Windesheim's academic requirements, while also ensuring our project group achieved a successful outcome. Through effective negotiation and compromise, I was able to strike a balance that allowed us to proceed with the project, resulting in a positive experience for all parties involved.
To commence the project, our team conducted thorough research to identify the most suitable libraries and models for addressing Stater's specific needs. After careful evaluation, we determined that TensorFlow and Scikit-learn were the optimal choices. Since Scikit-learn had been covered extensively in our coursework, we decided to leverage its capabilities for this project.
As part of my contribution, I developed a script capable of fetching the latest dataset from the American government's archives. To ensure clean and meaningful data, the script performed various preprocessing tasks, including the removal of stop words, normalization of text, and elimination of non-alphabetic characters. We then trained a SVM model on the preprocessed data using TF-IDF vectorization. However, due to the computational complexity of SVM, the training process took a substantial 47 hours to complete, yielding an accuracy of 59%.
During the course of the project, an exciting development took place—the release of the PaLM API at the Google IO event. Recognizing the potential value of this new resource, I promptly integrated it into our project and conducted a series of tests using TensorFlow. The initial evaluation of the cleaned data revealed an accuracy of 53%, which, while slightly lower than the SVM model, indicated promise. Curious to explore further, I also ran the PaLM API on non-cleaned data, which was anonymized to protect sensitive information. Surprisingly, the embeddings produced significantly better results, with an accuracy of 58%. This discovery emphasized the effectiveness of embeddings in handling non-cleaned data, showcasing their superiority over traditional methods.
Engaging in this project was a thoroughly enjoyable and highly instructive experience. Not only did it provide me with hands-on exposure to advanced data science techniques, but it also honed my skills in communication, problem-solving, and adaptability. I take great pride in successfully navigating the challenges that arose during the project, ultimately delivering a satisfactory outcome for Stater, fulfilling academic requirements, and fostering a collaborative and high-performing team environment. The lessons learned and achievements gained throughout this endeavour have significantly contributed to my growth as a data science professional.
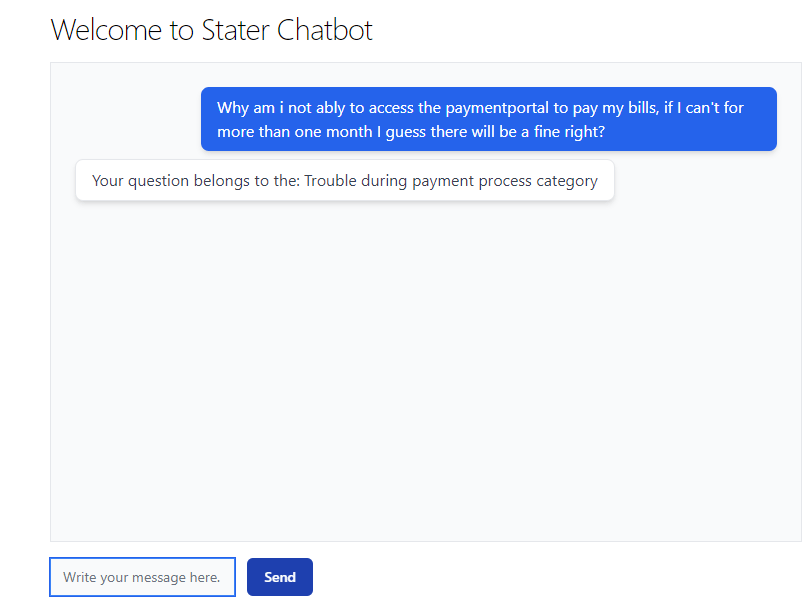
To facilitate the comparison of various models, we developed a chatbot that provides classification results based on the selected model. Users can specify their desired model through the chatbot's input field, enabling convenient and direct comparisons between different approaches. This user-friendly feature allows for efficient evaluation and selection of the most suitable model for specific text classification tasks. By incorporating this functionality, we aimed to streamline the model selection process and empower users to make informed decisions based on their specific requirements.
Stater gave the following feedback about our professionality: Well-executed, creative, open to adapting to the assignment, and handles feedback effectively. Enjoys working with data, demonstrating enthusiasm and clarity. Demonstrates learning ability.
Stater also gave the following summary about working with us: It was enjoyable working with them. It was impressive how they managed to create something remarkable in a team setting despite limited data and time constraints. They faced challenges along the way, but approached them with enthusiasm and effectively applied the knowledge they gained. It was valuable for them to learn that working in a data-oriented job, involving research, analysis, and product/POC development at a company, presents numerous challenges. It requires problem-solving skills, creativity, gathering information and data, and collectively adding value. On behalf of the team members, it was a highly successful collaboration.